How CDN Based Cache Warming Works
Cache warming operates by:- Identifying Slow Queries: Telemetry data is used to detect high-latency operations that could cause performance bottlenecks. The system prioritizes queries based on P90 latency measurements, ensuring that the slowest queries are targeted for warming.
- Building a Manifest: The system prioritizes the slowest queries and then compiles them into a manifest for caching. This manifest is stored in the CDN and fetched whenever the router needs it.
- Precomputing Query Plans: The cache warmer precomputes and stores query plans in the router, ensuring immediate availability during peak traffic periods. This precomputing occurs at the start of the router, as well as whenever the router restarts due to a configuration update triggered by a subgraph publish.
Key Characteristics of CDN Cache Warming
CDN based cache warming has several important characteristics that distinguish it from the in-memory fallback cache: Advantages:- Works from the first router start: Unlike in-memory fallback, CDN cache warming provides immediate benefits from the moment the router starts for the first time, with no cold start period.
- Targets slow queries strategically: It focuses on a curated set of queries that have slow planning times (identified through telemetry) and queries that have been manually added, ensuring the most impactful optimizations.
- Catches infrequent but slow queries: Even less regularly occurring queries that are slow to plan will be precomputed on startup, preventing occasional latency spikes.
- Limited coverage: Fast-to-plan queries that occur frequently are not included in the CDN cache manifest, as they don’t benefit significantly from precomputation.
Configuration & Customization
Enabling Cache Warming
- The feature is available to enterprise customers via the Cosmo interface.
- Organizations can activate it at the namespace level to target specific workloads.
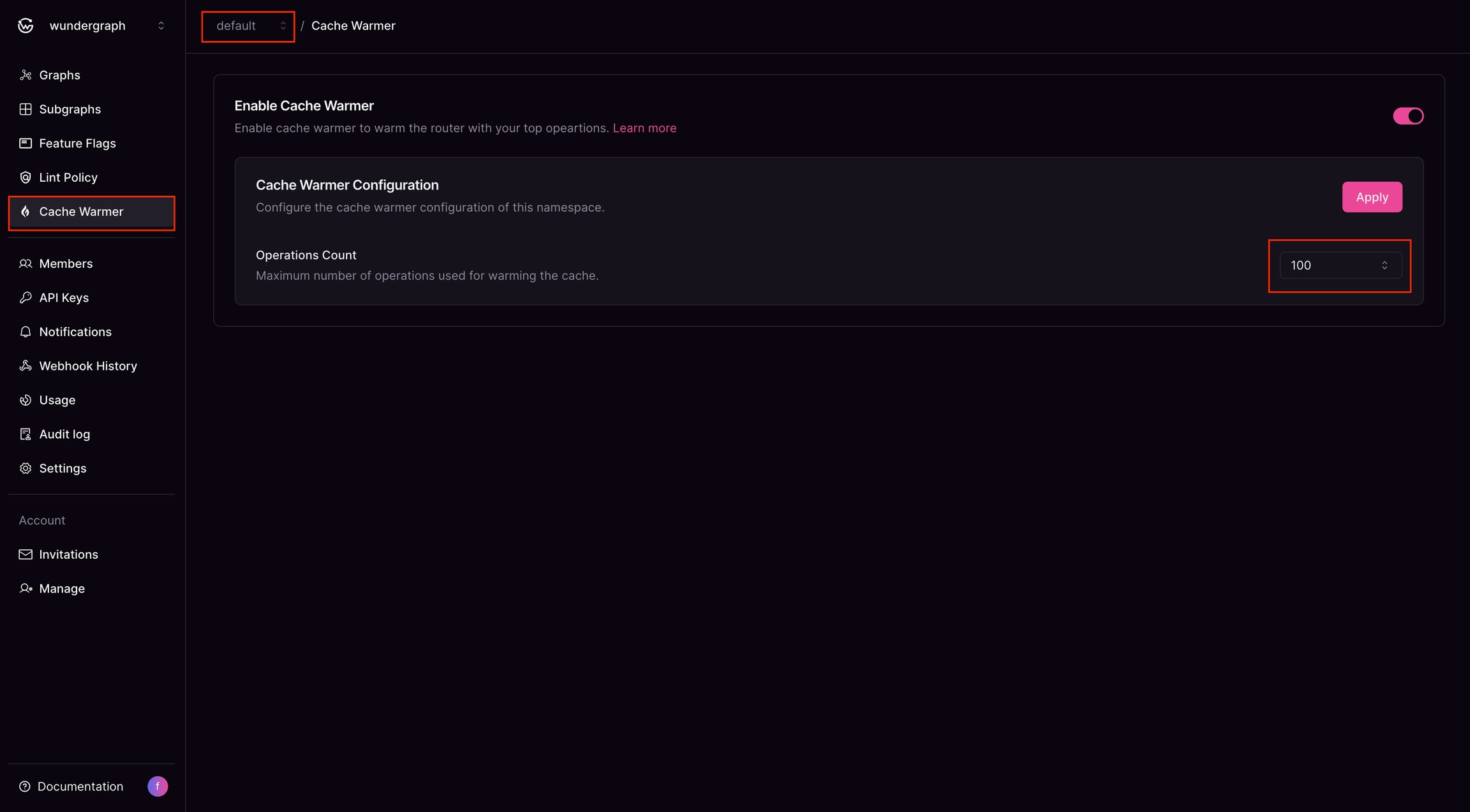
- Users can configure the maximum number of operations for cache warming.
- Operations are managed using a LIFO (Last-In, First-Out) policy, ensuring the latest operation is added while the oldest is removed once the limit is reached.
Router Configuration
To enable the cache warmer in the router, add the following configuration to your router configuration file:Cache Warmer Optimization
Three settings shape warmup throughput:workers, items_per_second, and item_delay. The timeout bounds how long startup will wait for warmup to complete. Tune them to balance warm-up speed against system load and deploy time.
workers is the number of concurrent workers processing warmup items. Each worker pulls from a shared queue. Raising workers increases parallelism but does not raise the items_per_second ceiling, since the rate limiter sits in front of the pool rather than per worker.
items_per_second is a ceiling, not a target. The router uses a rate limiter that prevents workers from exceeding this rate, but actual throughput can be lower when planning is slow or there are fewer items than the limit allows. The limit is shared across all workers, not applied per worker. A single rate limiter sits in front of the worker pool, so workers: 9 with items_per_second: 50 means the 9 workers collectively process at most 50 items per second, not 50 each.
item_delay is a fixed pause applied after each item is processed, per worker. It defaults to 0s (disabled). Reach for it when items_per_second alone is not enough. Planning some operations can take longer than one second, and when that happens the rate limiter has already moved to its next tick, so the next item starts immediately. item_delay enforces a minimum gap after every item, so a run of slow plans cannot burst the system. Use it together with items_per_second when warmup runs alongside production traffic and you need predictable headroom for subgraphs.
Size timeout based on the throughput the above three settings allow. Two things put a floor on warmup duration: the items_per_second rate limit, and the item_delay pause that each worker takes after every item. Whichever is slower wins.
For example, warming 200 items with 1 worker at 2 items per second takes at least 100 seconds — the rate limit sets the pace. Add item_delay: 1s and the floor rises to 200 seconds, because every item now also costs a full second of pause and there’s only one worker absorbing it. Doubling to 2 workers brings the delay’s contribution back down to 100 seconds, so the rate limit takes over again.
Actual runtime is always longer because each item also has to be planned.
If you are using the slow plan cache as the warmup source, to get an estimate of how many operations the router actually warms, inspect the cache warmer logs. The Warmup completed, Warmup timeout, and Warmup error messages all include a processed_items attribute. Use that number to size timeout for future restarts.
Tuning guidance
- For fastest warmup, raise
workersanditems_per_secondtogether. Workers without throughput headroom will idle. - For lowest startup load, lower
items_per_secondand keepworkersmodest. - For a hard floor on per-item spacing when some plans run slow, set
item_delay. It pairs withitems_per_secondrather than replacing it. - For predictable deploy time, keep
timeoutaligned with your deployment health-check window.
Customization Options
Manually Prioritized Operations Customers can add operations to the cache manually, ensuring critical queries are always warmed. It can be added using wgc.Manual Recompute from Studio
Users can manually recompute slow queries from the Cosmo Studio. Currently, recomputation only occurs when a manual operation is added or when the subgraph is published.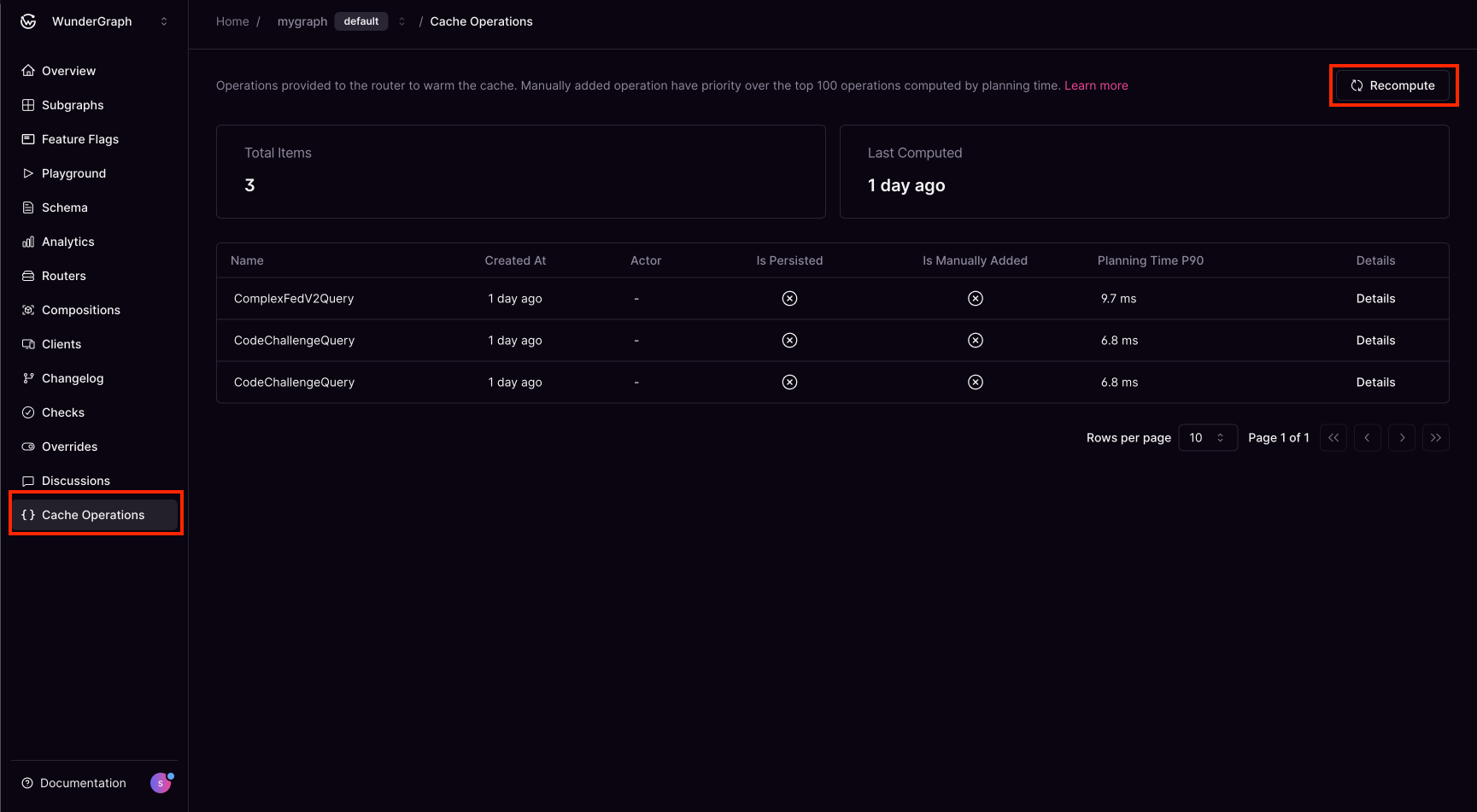
In-Memory Fallback Cache Warming
The in-memory fallback cache warming feature uses the slow plan cache to preserve query plans across hot config reloads and schema changes, reducing latency spikes during restarts.How It Works
The in-memory fallback relies on the slow plan cache — a secondary, bounded cache that tracks queries whose planning time exceeds a configurable threshold (slow_plan_cache_threshold, default 100ms). During normal operation, this cache is populated in two ways:
- On first plan: When a query is planned and its planning duration exceeds the threshold, the plan is stored in both the main cache and the slow plan cache.
- On eviction: If the main TinyLFU cache evicts a plan that is in the slow plan cache, the query plan won’t be recomputed and would simply be served from the slow plan cache.
When to Use the In-Memory Fallback
The in-memory fallback can be used either as a fallback method or as a primary method for cache warming. This depends on the router configuration; the defaults provided by the router enable it as a fallback to the Cosmo Cloud CDN cache warmer, which is a feature that needs to be enabled explicitly in Cosmo. However, it can also be used as the primary method of rewarming the plan cache. When the in-memory fallback is used with the Cosmo Cloud CDN cache warmer, the fallback is triggered when either:- Getting the list of operations from the CDN fails
- The request to the CDN succeeds but does not return a list of operations (either no operations are cached or the manifest has not been created yet)
The in-memory fallback cannot be used as a fallback for sources other than the Cosmo Cloud CDN cache warmer.
Key Characteristics of In-Memory Fallback
Advantages:- Coverage of expensive queries: By default, queries with planning times above the threshold (100ms) are preserved and warmed on reload, protecting slow-to-plan queries from cold-start latency. Users can lower the threshold to any positive duration (e.g.,
slow_plan_cache_threshold: 100ms) to capture all queries. Users can also set the duration to 1 nanosecond (slow_plan_cache_threshold: 1ns), this would ensure that all queries are cached in the fallback, and thus would be available to rewarm the cache upon reloads. - Eliminates reload spikes for expensive queries: You won’t experience query planning spikes for queries above the threshold after configuration or schema reloads. Users can tune the threshold to cover more or fewer queries.
- Cold start on first start: The first router start will experience normal cache warming latency, as there’s no existing cache to preserve.
Configuration
The in-memory fallback can be enabled as a fallback for the CDN cache warmer. To do this, ensure:- Cache warming is enabled in the router configuration (
cache_warmup.enabled: true) source.cdn.enabledis set totrue(this is true by default and does not need to be explicitly specified)in_memory_fallbackis set totrue(default)
- Cache warming is enabled in the router configuration (
cache_warmup.enabled: true) source.cdn.enabledis set tofalse(this needs to be specified explicitly, as the default is true)in_memory_fallbackis set totrue(default)
Slow Plan Cache
When in-memory fallback is enabled, the cache the in memory fallback uses is the Slow Plan Cache. This is different from the main query plan cache which uses a TinyLFU (Least Frequently Used) eviction policy, which is optimized for frequently accessed items. However, this can cause problems for queries that are slow to plan but infrequently accessed — the LFU policy may evict them in favor of cheaper, more frequent queries. When an expensive query is evicted and re-requested, the router must re-plan it from scratch, causing a latency spike. The slow plan cache is a secondary cache that protects these slow-to-plan queries from eviction. It is automatically enabled whenin_memory_fallback is set to true.
How It Works
- When a query is planned for the first time, its planning duration is measured.
- If the planning duration exceeds the configured threshold (
slow_plan_cache_threshold, default 100ms), the query plan is stored in both the main cache and the slow plan cache. - If the main cache later evicts this plan (due to LFU pressure from more frequent queries), the OnEvict hook pushes it to the slow plan cache (if it meets the threshold).
- On subsequent requests, if the plan is not found in the main cache, the router checks the slow plan cache before re-planning. If found, the plan is served immediately and re-inserted into the main cache.
- During config reloads, slow plan cache entries are used as the warmup source, ensuring slow queries survive cache rebuilds.
Cache Size and Eviction
The slow plan cache has a configurable maximum size (slow_plan_cache_size, default 300). When the cache is full and a new expensive query needs to be added:
- The new query’s planning duration is compared to the shortest duration in the cache.
- If the new query is more expensive (took longer to plan), it replaces the least expensive entry.
- If the new query is cheaper or equal, it is not added. This ensures the cache always contains the most expensive queries.
Whenever an existing item in the cache is attempted to be added to the cache while full, we will not remove the entry and will only update it’s plan time duration if it was higher than the previous duration it took to plan. This way we only consider the worst case planning duration.
Configuration
The slow plan cache is configured through the engine configuration:Tuning
You can tune the threshold and cache size to control warmup coverage:- Lower threshold → more queries protected: Setting
slow_plan_cache_threshold: 1nscaptures all queries regardless of planning time. This gives you full “carry forward everything” behaviour similar to preserving the entire plan cache. - Higher cache size → more entries held: Increase
slow_plan_cache_sizeto hold more entries. For full coverage, set it to match or exceedexecution_plan_cache_size. - Tradeoff: Lower thresholds and larger cache sizes increase memory usage but provide broader warmup coverage.
Observability
Slow plan cache hits are counted as regular plan cache hits — thewg.engine.plan_cache_hit attribute is set to true for hits from either the main cache or the slow plan cache. There is no separate observability signal for slow plan cache hits.