> ## Documentation Index
> Fetch the complete documentation index at: https://cosmo-docs.wundergraph.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Grafana
> Using Grafana with your Cosmo Router allows you to track metrics such as network traffic, cache status, and system performance, all in real-time. This enhanced visibility helps in quickly identifying anomalies, diagnosing issues, and optimizing network efficiency.
## Introduction
The included dashboards are particularly useful for developers, enabling you to quickly understand how Grafana can aggregate metrics and present them in a meaningful way. You can leverage these templates as a foundation, customizing them to meet your specific needs or integrating them with other data sources for a comprehensive monitoring solution.
## What are we going to do?
The cosmo repository provides us with all the necessary pre-defined configurations
Makefile targets make it easy to start and stop the containers
We need to make sure our Grafana can query for the metrics
We're done. Now it's your turn to explore and build your own visualizations
## Existing Dashboards
The current dashboards are located [here](https://github.com/wundergraph/cosmo/tree/main/docker/grafana/provisioning/dashboards).
## Prerequisites
In order to run Grafana locally you need the following tools installed:
* **Docker Compose**: Ensure you have Docker Compose installed to manage multi-container Docker applications. This will be crucial for setting up Grafana and other services.
* **Make**: Install Make to automate and streamline the setup process by running defined tasks, ensuring a smooth and efficient integration.
## Setup
First you need to checkout [cosmo](https://github.com/wundergraph/cosmo) locally.
Navigate to the root of the project in your terminal and run the following command
```bash theme={"system"}
make infra-debug-up
```
This will automatically setup Prometheus and Grafana.
Grafana comes with pre-configured datasources: ClickHouse and Prometheus. This setup allows for immediate access to visualize and analyze your data.
## Configure the router
To enable Grafana to visualize data effectively, you need to supply metrics to Prometheus. This involves adding specific configurations to the YAML router setup before initiating the router. Update your YAML router config with the necessary metrics endpoints or configurations to ensure seamless data flow from Prometheus to Grafana.
When using OpenTelemetry (OTEL), metrics are collected via OpenTelemetry SDKs or agents, which can be configured to instrument your application code. These metrics are then exported to Prometheus using a Prometheus remote write exporter, allowing Prometheus to scrape and store the metrics data.
In contrast, using the Prometheus Go client involves directly instrumenting your Go application with Prometheus client libraries. These libraries expose metrics directly through an HTTP endpoint that Prometheus can scrape at regular intervals. This method typically requires more manual setup to define and manage the metrics you wish to expose.
There are two ways to configure the router for this use case:
1. **Using OpenTelemetry (OTEL)**: Instrument your application with OpenTelemetry SDKs or agents. Export the collected metrics to Prometheus using a Prometheus remote write exporter. This approach allows for a more standardized integration with OpenTelemetry's ecosystem.
2. **Using Prometheus Go Client**: Directly instrument your Go application using Prometheus client libraries. This involves exposing metrics through an HTTP endpoint for Prometheus to scrape. This method provides more control over the metrics definition and is suitable for Go applications.
### Configure Prometheus endpoint in the router
Check the prometheus config in the `./docker`directory. By default it defines scrape configs where metrics are polled from
```yaml theme={"system"}
global:
scrape_interval: 15s
evaluation_interval: 10s
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: "cosmo"
scrape_interval: 2s
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
# Allows to scrape metrics from the host machine
# https://docs.docker.com/desktop/networking/#i-cannot-ping-my-containers
- targets: ["host.docker.internal:8041"]
- job_name: "apollo"
scrape_interval: 2s
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
# Allows to scrape metrics from the host machine
# https://docs.docker.com/desktop/networking/#i-cannot-ping-my-containers
- targets: ["host.docker.internal:8051"]
```
The Prometheus configuration above sets up two scrape jobs, "cosmo" and "apollo," each set with a scrape interval of 2 seconds. This means Prometheus will collect metrics every 2 seconds from each specified target. The targets "host.docker.internal:8041" for "cosmo" and "host.docker.internal:8051" for "apollo" are configured to be scraped from the host machine. The metrics are accessible via the default path `/metrics`. This setup allows Prometheus to retrieve metrics data from specified endpoints running in Docker, leveraging the `host.docker.internal` domain to access containers from the host.
We need to instruct the router to expose one of these endpoint
```yaml theme={"system"}
telemetry:
metrics:
prometheus:
graphql_cache: true # enable cache metrics
engine_stats:
subscriptions: true #enable subscription metrics
listen_addr: localhost:8041 # matches scrape config "cosmo"
```
### Configure Open Telemtry to push to Prometheus
The OpenTelemetry (otel) configuration for pushing data to Prometheus looks similar to the Prometheus configuration, focusing on setting up collection intervals and specifying targets for metrics.
In contrast to exposing an endpoint, configuring an exporter allows us to push data directly to a Prometheus endpoint via **HTTP**. This method involves setting up the appropriate exporter configuration to actively send the required telemetry data to **Prometheus** and visualized.
```yaml theme={"system"}
telemetry:
metrics:
otlp:
graphql_cache: true
engine_stats:
subscriptions: true
# router runtime is enabled by default in the Prometheus config
# but must be enabled in the OpenTelemetry config
router_runtime: true
exporters:
# Prometheus container endpoint. Not the router metrics endpoint
- endpoint: "localhost:9090"
exporter: http
path: /api/v1/otlp/v1/metrics
temporality: cumulative # Important
```
## Login to Grafana
You can access Grafana on [http://localhost:9300](http://localhost:9300) using the default credentials, `admin` for both the username and password.
### Viewing Dashboards
Once logged in to Grafana, you will be able to see at least two essential dashboards:
1. **Router Cache Metrics Dashboard**: This dashboard offers insights into the caching operations of the router, helping you monitor cache efficiency and performance.
2. **Go Runtime Metrics Dashboard**: Here, you can observe metrics related to the Go runtime environment, such as memory usage and goroutine counts, providing a deeper understanding of your application's operational health.
These dashboards are designed to help you effectively monitor and analyze the performance of your systems.
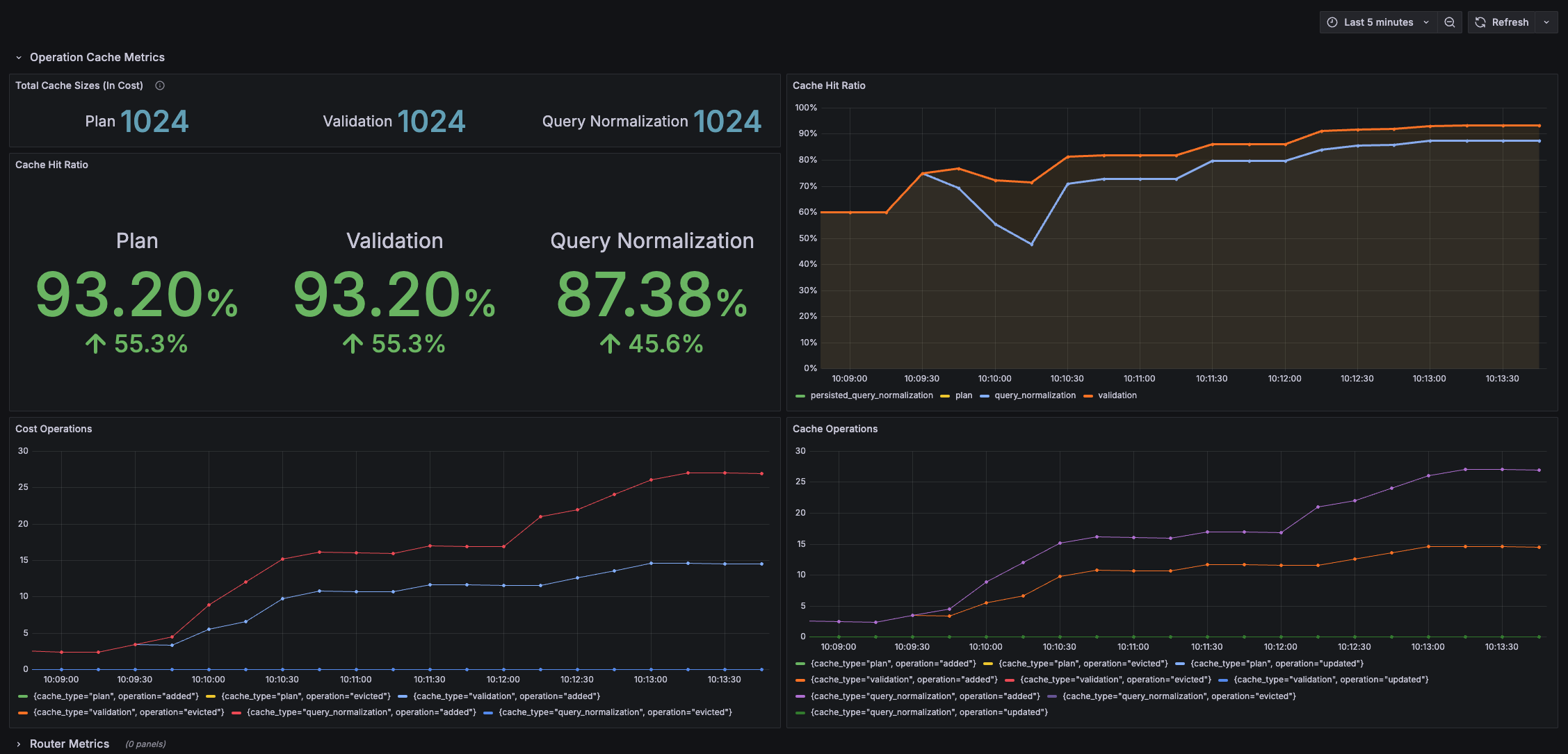
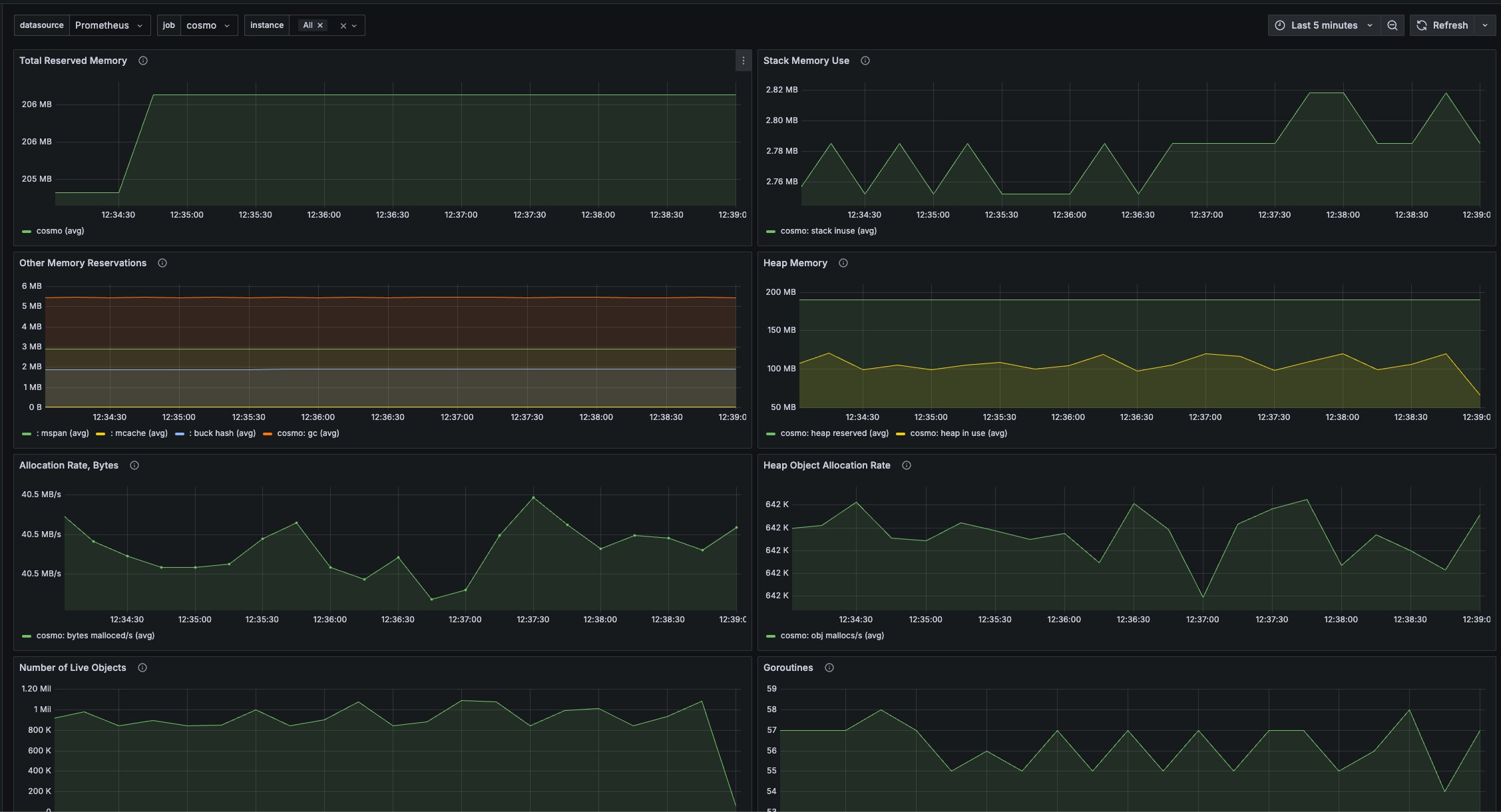 Here are a few paths you can take to explore the comprehensive metrics offered by your router:
1. **Examine the Existing Dashboards**: Begin by reviewing the pre-built dashboards, which provide detailed insights into various aspects of your router's performance and behaviors.
2. **Create Custom Dashboards**: If you have specific metrics in mind or unique monitoring requirements, you can craft your own dashboards to better fit your needs and objectives.
3. **Explore the Diverse Metrics**: Delve into the wide array of metrics available from your router to gain a comprehensive understanding of its operations, covering not just cache but many other performance indicators as well.
Feel free to choose the approach that best suits your objectives.
### Removing Containers
To remove containers, you have two options:
1. `make infra-debug-down`: This command will stop and remove the running containers without affecting the existing Docker volumes.
2. `make infra-debug-down-v`: Use this command if you need a clean slate by removing both the containers and the existing Docker volumes. This is particularly useful when you want to start fresh, without any pre-existing metrics in Prometheus.
Here are a few paths you can take to explore the comprehensive metrics offered by your router:
1. **Examine the Existing Dashboards**: Begin by reviewing the pre-built dashboards, which provide detailed insights into various aspects of your router's performance and behaviors.
2. **Create Custom Dashboards**: If you have specific metrics in mind or unique monitoring requirements, you can craft your own dashboards to better fit your needs and objectives.
3. **Explore the Diverse Metrics**: Delve into the wide array of metrics available from your router to gain a comprehensive understanding of its operations, covering not just cache but many other performance indicators as well.
Feel free to choose the approach that best suits your objectives.
### Removing Containers
To remove containers, you have two options:
1. `make infra-debug-down`: This command will stop and remove the running containers without affecting the existing Docker volumes.
2. `make infra-debug-down-v`: Use this command if you need a clean slate by removing both the containers and the existing Docker volumes. This is particularly useful when you want to start fresh, without any pre-existing metrics in Prometheus.